# !pip install -Uqq fastbook kaggle waterfallcharts treeinterpreter dtreeviz==2.2.2Kaggle insurance competition 2024
Regression with an Insurance Dataset
This notebook trains a random forest model to predict car insurance premium for a given customer.
It is for a Kaggle competition - https://www.kaggle.com/competitions/playground-series-s4e12/overview
The tabular dataset includes insurance customer data, along with the premium each of the customers pays.
The model’s predictions were submitted to the competition and placed 818/2392 on the private leaderboard.
In addition to entering the competition, I also explored techniques to see which features of the data are most important for making predictions, and how much these features contribute to the model’s predictions - over the entire dataset or for a specific customer. This ability to look closely at the causes of predictions is one of the strengths of tree-based models like random forests.
Finally, a neural network was trained on the tabular dataset, and ensembled with the random forest model. This ensembled performed better than either the neural network or the random forest model alone.
# imports
#hide
from fastbook import *
from kaggle import api
from pandas.api.types import is_string_dtype, is_numeric_dtype, is_categorical_dtype
from fastai.tabular.all import *
from sklearn.ensemble import RandomForestRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn import metrics
import dtreeviz
from IPython.display import Image, display_svg, SVG
from pathlib import Path
import pandas as pd
pd.options.display.max_rows = 20
pd.options.display.max_columns = 8Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /Users/mikeg/.kaggle/kaggle.json'!ls $pathinsurance_competition.ipynb to.pkl
sample_submission.csv train.csv
submission.csv valid_xs_final.pkl
test.csv xs_final.pklpath = Path.cwd()df = pd.read_csv(path/"train.csv", low_memory=False)df.head()| id | Age | Gender | Annual Income | ... | Smoking Status | Exercise Frequency | Property Type | Premium Amount | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 19.0 | Female | 10049.0 | ... | No | Weekly | House | 2869.0 |
| 1 | 1 | 39.0 | Female | 31678.0 | ... | Yes | Monthly | House | 1483.0 |
| 2 | 2 | 23.0 | Male | 25602.0 | ... | Yes | Weekly | House | 567.0 |
| 3 | 3 | 21.0 | Male | 141855.0 | ... | Yes | Daily | Apartment | 765.0 |
| 4 | 4 | 21.0 | Male | 39651.0 | ... | Yes | Weekly | House | 2022.0 |
5 rows × 21 columns
cols = df.columns
df.columnsIndex(['id', 'Age', 'Gender', 'Annual Income', 'Marital Status',
'Number of Dependents', 'Education Level', 'Occupation', 'Health Score',
'Location', 'Policy Type', 'Previous Claims', 'Vehicle Age',
'Credit Score', 'Insurance Duration', 'Policy Start Date',
'Customer Feedback', 'Smoking Status', 'Exercise Frequency',
'Property Type', 'Premium Amount'],
dtype='object')Find any ordinal columns which have a natural order to them, but where the ordering is not represented in the levels of the data.
for col in cols:
print(df[col].unique())[ 0 1 2 ... 1199997 1199998 1199999]
[19. 39. 23. 21. 29. 41. 48. 44. 56. 25. 40. 18. 59. 34. 22. 46. 49. 42. 43. 64. 52. 37. 58. 50. 35. 61. 31. 54. 45. 30. 33. 28. 62. 53. 47. 27. nan 38. 63. 32. 36. 20. 51. 55. 57. 24. 60. 26.]
['Female' 'Male']
[ 10049. 31678. 25602. ... 125361. 137940. 40368.]
['Married' 'Divorced' 'Single' nan]
[ 1. 3. 2. 0. 4. nan]
["Bachelor's" "Master's" 'High School' 'PhD']
['Self-Employed' nan 'Employed' 'Unemployed']
[22.59876067 15.56973099 47.17754929 ... 47.09690866 13.6616783 11.48348225]
['Urban' 'Rural' 'Suburban']
['Premium' 'Comprehensive' 'Basic']
[ 2. 1. 0. nan 3. 4. 5. 6. 7. 8. 9.]
[17. 12. 14. 0. 8. 4. 11. 10. 9. 6. 19. 3. 15. 16. 5. 7. 18. 1. 2. 13. nan]
[372. 694. nan 367. 598. 614. 807. 398. 685. 635. 431. 597. 511. 498. 584. 420. 595. 799. 773. 798. 543. 416. 425. 486. 795. 495. 449. 803. 421. 695. 713. 589. 812. 382. 469. 530. 538. 842. 575.
794. 836. 784. 439. 381. 801. 624. 497. 359. 662. 703. 426. 331. 679. 375. 321. 531. 622. 464. 418. 534. 454. 502. 823. 319. 660. 371. 562. 488. 577. 791. 638. 438. 779. 310. 748. 392. 446. 593.
576. 493. 479. 826. 332. 616. 716. 602. 343. 377. 788. 758. 571. 554. 682. 641. 360. 522. 728. 388. 535. 519. 651. 829. 620. 776. 835. 432. 607. 705. 644. 686. 797. 509. 831. 529. 774. 592. 843.
738. 781. 766. 364. 349. 692. 574. 324. 632. 379. 434. 442. 764. 429. 683. 770. 696. 611. 436. 482. 636. 609. 374. 566. 537. 648. 578. 707. 581. 541. 845. 441. 718. 630. 586. 780. 401. 757. 646.
752. 665. 506. 336. 430. 424. 459. 786. 447. 339. 516. 590. 456. 334. 645. 520. 453. 647. 588. 585. 489. 532. 772. 380. 490. 573. 712. 437. 342. 792. 583. 487. 587. 539. 793. 691. 759. 494. 762.
653. 391. 472. 560. 659. 810. 734. 731. 765. 407. 440. 656. 815. 415. 527. 613. 402. 783. 751. 658. 465. 335. 559. 536. 603. 657. 742. 846. 739. 689. 468. 513. 328. 723. 626. 505. 617. 698. 725.
423. 744. 338. 743. 348. 389. 450. 833. 704. 667. 652. 664. 825. 496. 504. 629. 580. 678. 572. 345. 397. 346. 414. 460. 841. 596. 674. 822. 483. 405. 314. 565. 693. 485. 832. 749. 830. 451. 387.
561. 775. 326. 302. 393. 727. 463. 329. 730. 304. 817. 445. 768. 567. 639. 491. 582. 542. 761. 819. 778. 523. 787. 350. 618. 548. 466. 702. 394. 844. 508. 756. 805. 476. 820. 625. 544. 767. 473.
521. 785. 839. 553. 828. 325. 461. 547. 594. 724. 827. 309. 378. 492. 687. 722. 452. 568. 816. 470. 555. 709. 417. 719. 591. 396. 834. 533. 457. 604. 796. 477. 631. 341. 433. 847. 637. 684. 386.
720. 499. 733. 697. 706. 745. 721. 612. 552. 351. 365. 818. 808. 569. 481. 715. 406. 564. 501. 729. 524. 361. 484. 736. 518. 467. 790. 782. 699. 760. 403. 563. 316. 710. 755. 802. 608. 376. 318.
711. 308. 848. 557. 681. 680. 478. 601. 821. 558. 655. 301. 507. 546. 824. 677. 404. 320. 663. 356. 410. 654. 673. 337. 619. 621. 462. 672. 763. 806. 649. 627. 688. 849. 528. 643. 549. 746. 732.
515. 800. 444. 579. 671. 811. 615. 737. 661. 306. 363. 556. 714. 690. 312. 352. 769. 362. 642. 753. 307. 623. 411. 510. 634. 354. 628. 366. 838. 385. 353. 837. 599. 500. 668. 300. 373. 814. 474.
409. 771. 726. 358. 413. 471. 514. 551. 650. 475. 676. 384. 419. 754. 517. 311. 813. 443. 368. 701. 303. 750. 804. 357. 455. 395. 708. 545. 717. 777. 313. 315. 600. 422. 383. 340. 540. 512. 370.
435. 427. 408. 809. 605. 633. 675. 503. 347. 740. 327. 412. 322. 526. 369. 840. 448. 400. 317. 610. 570. 735. 344. 480. 670. 399. 666. 669. 550. 458. 390. 333. 789. 741. 700. 640. 525. 305. 323.
355. 747. 606. 330. 428.]
[ 5. 2. 3. 1. 4. 6. 8. 9. 7. nan]
['2023-12-23 15:21:39.134960' '2023-06-12 15:21:39.111551' '2023-09-30 15:21:39.221386' ... '2021-04-28 15:21:39.129190' '2019-11-14 15:21:39.201446' '2020-10-19 15:21:39.118178']
['Poor' 'Average' 'Good' nan]
['No' 'Yes']
['Weekly' 'Monthly' 'Daily' 'Rarely']
['House' 'Apartment' 'Condo']
[2869. 1483. 567. ... 4937. 4507. 4925.]There aren’t many ordinal columns, education level might be the only one worth considering.
edu_levels = ('High School', "Bachelor's", "Master's", 'PhD')
df['Education Level'] = df['Education Level'].astype('category')
df["Education Level"] = df['Education Level'].cat.set_categories(edu_levels, ordered=True)Dependent Variable
The dependent variable is the premium amount column. We’ll take the Root Mean Squared Log Error (RMSLE) as the metric to evaluate the model.
dep_var = "Premium Amount"Root mean square log error
The function is available in sklearn version 1.4 and above as metrics.root_mean_squared_log_error but the fastai library imports some things from an earlier library. We can implement it manually like so:
def rmsle(x, y): return math.sqrt(((np.log1p(x) - np.log1p(y))**2).mean())We’re interested in the log of the premium amount. log1p is the natural logarithm of 1 plus the input array, which is the same as sklearn’s mean_squared_log_error. The inverse is is
np.expm1()df[dep_var] = np.log1p(df[dep_var])df[dep_var]0 7.962067
1 7.302496
2 6.342121
3 6.641182
4 7.612337
...
1199995 7.173192
1199996 6.711740
1199997 5.918894
1199998 6.391917
1199999 7.816417
Name: Premium Amount, Length: 1200000, dtype: float64Split the dates into various features like year, quarter, month etc. Perhaps there’s a promotion that’s run in a particular month that affects the premium amount.
df = add_datepart(df, 'Policy Start Date')/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:25: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.df.columnsIndex(['id', 'Age', 'Gender', 'Annual Income', 'Marital Status',
'Number of Dependents', 'Education Level', 'Occupation', 'Health Score',
'Location', 'Policy Type', 'Previous Claims', 'Vehicle Age',
'Credit Score', 'Insurance Duration', 'Customer Feedback',
'Smoking Status', 'Exercise Frequency', 'Property Type',
'Premium Amount', 'Policy Start Year', 'Policy Start Month',
'Policy Start Week', 'Policy Start Day', 'Policy Start Dayofweek',
'Policy Start Dayofyear', 'Policy Start Is_month_end',
'Policy Start Is_month_start', 'Policy Start Is_quarter_end',
'Policy Start Is_quarter_start', 'Policy Start Is_year_end',
'Policy Start Is_year_start', 'Policy Start Elapsed'],
dtype='object')Process the dates in the test set too.
df_test = pd.read_csv(path/"test.csv", low_memory=False)
df_test = add_datepart(df_test, 'Policy Start Date')/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:25: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.Handle strings and missing data.
Out of the box, sklearn cannot do either. Instead we will use fastai’s class TabularPandas, which wraps a Pandas DataFrame and provides a few conveniences. To populate a TabularPandas, we will use two TabularProcs, Categorify and FillMissing. A TabularProc is like a regular Transform, except that:
- It returns the exact same object that’s passed to it, after modifying the object in place.
- It runs the transform once, when data is first passed in, rather than lazily as the data is accessed.
Categorify is a TabularProc that replaces a column with a numeric categorical column. FillMissing is a TabularProc that replaces missing values with the median of the column, and creates a new Boolean column that is set to True for any row where the value was missing. These two transforms are needed for nearly every tabular dataset, so this is a good starting point for data processing.
procs = [Categorify, FillMissing]The samples seem to be taken from overlapping time periods, so there’s no need to take the validation set from the latest entries of the training set.
df['Policy Start Year'].min(), df_test['Policy Start Year'].min(), df['Policy Start Year'].max(), df_test['Policy Start Year'].max()(2019, 2019, 2024, 2024)df['Policy Start Year']0 2023
1 2023
2 2023
3 2024
4 2021
...
1199995 2023
1199996 2022
1199997 2021
1199998 2021
1199999 2020
Name: Policy Start Year, Length: 1200000, dtype: int32cont, cat = cont_cat_split(df, 1, dep_var=dep_var)
cont, cat(['id',
'Age',
'Annual Income',
'Number of Dependents',
'Health Score',
'Previous Claims',
'Vehicle Age',
'Credit Score',
'Insurance Duration',
'Policy Start Year',
'Policy Start Month',
'Policy Start Week',
'Policy Start Day',
'Policy Start Dayofweek',
'Policy Start Dayofyear',
'Policy Start Elapsed'],
['Gender',
'Marital Status',
'Education Level',
'Occupation',
'Location',
'Policy Type',
'Customer Feedback',
'Smoking Status',
'Exercise Frequency',
'Property Type',
'Policy Start Is_month_end',
'Policy Start Is_month_start',
'Policy Start Is_quarter_end',
'Policy Start Is_quarter_start',
'Policy Start Is_year_end',
'Policy Start Is_year_start'])Make a tabular pandas object
splits = RandomSplitter(valid_pct = 0.2)(range_of(df))
splits((#960000) [729083,728335,909947,233536,435159,1020048,671167,490966,921659,399765...],
(#240000) [637542,1128918,893682,648385,1100506,761290,831478,266883,499422,851477...])to = TabularPandas(df, procs, cat, cont, y_names=dep_var, splits=splits)/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:314: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
len(to.train), len(to.valid)(960000, 240000)The items in the TabularPandas object are displayed with their string representation if we use show, but the underlying data is all numeric and is stored in the items attribute.
to.show(3)| Gender | Marital Status | Education Level | Occupation | Location | Policy Type | Customer Feedback | Smoking Status | Exercise Frequency | Property Type | Policy Start Is_month_end | Policy Start Is_month_start | Policy Start Is_quarter_end | Policy Start Is_quarter_start | Policy Start Is_year_end | Policy Start Is_year_start | Age_na | Annual Income_na | Number of Dependents_na | Health Score_na | Previous Claims_na | Vehicle Age_na | Credit Score_na | Insurance Duration_na | id | Age | Annual Income | Number of Dependents | Health Score | Previous Claims | Vehicle Age | Credit Score | Insurance Duration | Policy Start Year | Policy Start Month | Policy Start Week | Policy Start Day | Policy Start Dayofweek | Policy Start Dayofyear | Policy Start Elapsed | Premium Amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 729083 | Male | Married | PhD | Self-Employed | Rural | Comprehensive | Poor | No | Rarely | House | False | False | False | False | False | False | False | False | False | False | True | False | False | False | 729083 | 23.0 | 11823.0 | 0.0 | 41.384293 | 1.0 | 11.0 | 727.0 | 4.0 | 2023 | 5 | 18 | 5 | 4 | 125 | 1.683300e+09 | 4.779123 |
| 728335 | Male | Single | PhD | Unemployed | Rural | Basic | Poor | Yes | Rarely | House | False | False | False | False | False | False | False | False | False | False | False | False | True | False | 728335 | 45.0 | 6655.0 | 0.0 | 23.327639 | 3.0 | 18.0 | 595.0 | 7.0 | 2020 | 5 | 21 | 18 | 0 | 139 | 1.589815e+09 | 7.395721 |
| 909947 | Male | Single | PhD | Employed | Suburban | Comprehensive | Poor | No | Daily | Apartment | True | False | False | False | False | False | False | False | False | False | False | False | False | False | 909947 | 31.0 | 12645.0 | 0.0 | 21.060629 | 0.0 | 14.0 | 817.0 | 2.0 | 2023 | 4 | 17 | 30 | 6 | 120 | 1.682868e+09 | 6.001415 |
to.items.head(3)| id | Age | Gender | Annual Income | ... | Previous Claims_na | Vehicle Age_na | Credit Score_na | Insurance Duration_na | |
|---|---|---|---|---|---|---|---|---|---|
| 729083 | 729083 | 23.0 | 2 | 11823.0 | ... | 2 | 1 | 1 | 1 |
| 728335 | 728335 | 45.0 | 2 | 6655.0 | ... | 1 | 1 | 2 | 1 |
| 909947 | 909947 | 31.0 | 2 | 12645.0 | ... | 1 | 1 | 1 | 1 |
3 rows × 41 columns
to.classes['Education Level']['#na#', 'High School', "Bachelor's", "Master's", 'PhD']The ordering of the categories was preserved.
Checkpoint
save_pickle(path/'to.pkl', to)to = load_pickle(path/'to.pkl')Train a decision tree model
Define the dependent and independent variables.
xs, y = to.train.xs, to.train.y
valid_xs, valid_y = to.valid.xs, to.valid.yNow that all the data is numeric and there are no missing values, we can train a decision tree model.
m = DecisionTreeRegressor(max_leaf_nodes=9)
m.fit(xs, y)DecisionTreeRegressor(max_leaf_nodes=9)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_leaf_nodes=9)
Take a sample 500 from the training set so that we don’t have a huge plot
to.items['Annual Income'].plot.hist(title='Annual Income', bins=50).plot()[]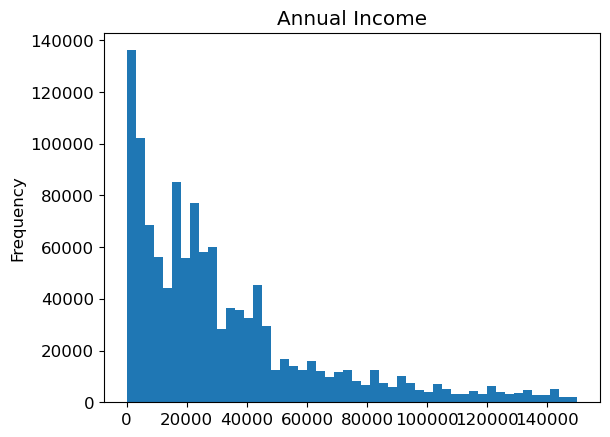
Visualizing the data splits made by the initial decision tree
sample_idx = np.random.permutation(len(y))[:1000]
viz_rmodel = dtreeviz.model(model=m, X_train=xs.iloc[sample_idx], y_train=y.iloc[sample_idx], feature_names=xs.columns, target_name=dep_var)
viz_rmodel.view(orientation='LR')/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but DecisionTreeRegressor was fitted with feature names
The ordering of boolean columns such as Age_na for whether the age column was missing is preserved, with False=1 and True=2
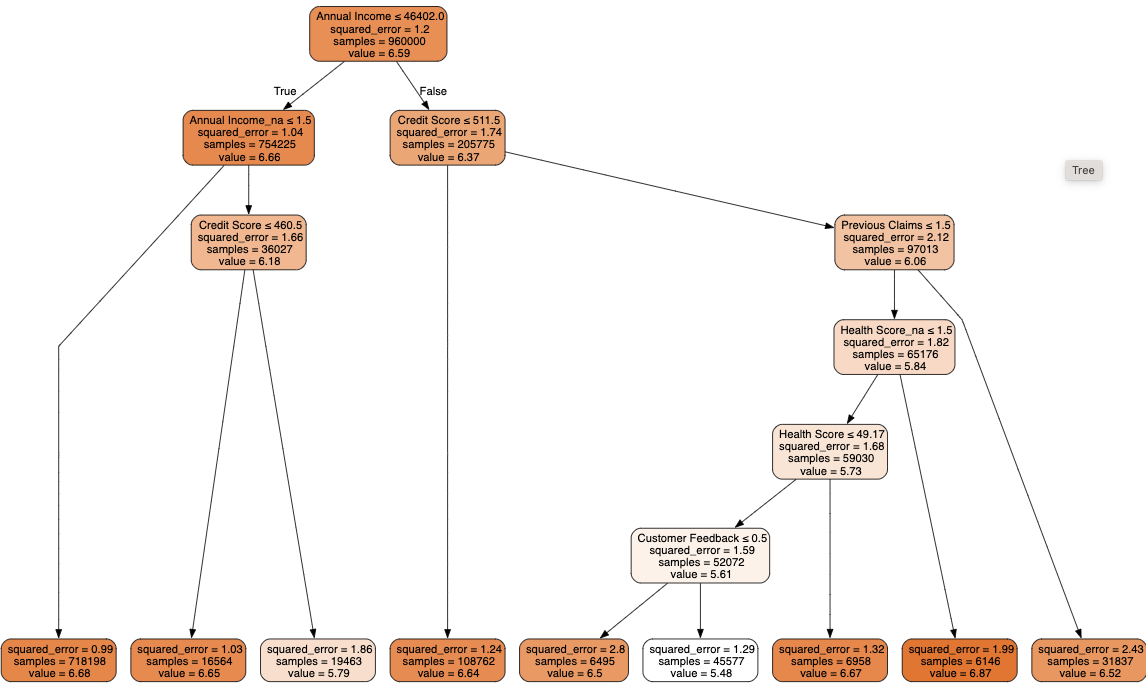
draw_tree(m, xs, size=10, leaves_parallel=True, precision=2)
The decision tree is making some splits which result in groups with a larger error in one group and a smaller error in the other group. The group with the smaller error is always the largest of the two groups. This is probably ok, since the model is trying to find the split which gives the largest overall reduction in the squared error across the two groups.
The previous examples i’ve worked on though, had splits which reduced the error in both groups - so pay attention to this when interpreting the results. At the end of the decision tree, the average of the weighted errors in the leaf nodes needs to be less than the average of the errors in the parent node, otherwise the model is worse than just predicting the mean.
Initial observations
Annual income is a strong predictor of premium amount the group earning under 46k has a higher premium amount than the group earning over 46k. For the group earning over 46k, the prediction of premium price for the average of this group is worse than the mean prediction for the entire dataset, but the group only contains 205775 samples compared with 754225 in the group earning under 46k where the prediction for the mean of the group is better than the mean prediction for the entire dataset.
For the group earning under 46k, the next most infomative split is whether their income amount is provided or not. For those where the income amount isn’t provided, the next most informative split is credit score. For those with income amount provided (as some amount below 46k) this ends in a leaf node where the squared error for the group of 720,000 people is 1.0 compared with 1.21 at the parent node. Further splits in the tree will lead to finer categories, potentially some splits for this lower income group will to a further reduction in the error.
Other interesting splits are: - If the number of previous claims is 2 or more, the premium amount is higher than if the number of previous claims is 1 or 0. - Policy holders who have just joined pay a higher premium than those who have held a policy for longer. - Policy holders with a higher health score pay more than those with a lower health score. - Policy holders with a high credit score pay more than those with a low credit score.
how many missing incomes are there?
to.xs.loc[to.xs['Annual Income_na'] == 1]['Annual Income'].describe()count 1.155051e+06
mean 3.274522e+04
std 3.217951e+04
min 1.000000e+00
25% 8.001000e+03
50% 2.391100e+04
75% 4.463400e+04
max 1.499970e+05
Name: Annual Income, dtype: float64to.xs.loc[to.xs['Annual Income_na'] == 2]['Annual Income'].describe()count 44949.000000
mean 23897.001953
std 0.000000
min 23897.000000
25% 23897.000000
50% 23897.000000
75% 23897.000000
max 23897.000000
Name: Annual Income, dtype: float64Here we can see that in the columns where the income is not provided, the income amount is set to the average of the income column. There are 50,000 missing values in the income column compared with 1.15 million present values. 0.43% of the values are missing. We shouldn’t worry about this 5% too much.
Let’s build a big tree!
The previous tree stopped at max leaf nodes = 9.
m = DecisionTreeRegressor()
m.fit(xs, y)DecisionTreeRegressor()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor()
RMSE
Make a function to calculate the model’s root mean square error on the predictions.
We’ve already taken the log of the premium amounts in the training and validation sets, so this is really RMSLE.
def r_mse(pred, y): return math.sqrt(((pred-y)**2).mean())
def m_rmse(m, xs, y): return r_mse(m.predict(xs), y)m_rmse(m, xs, y), m_rmse(m, valid_xs, valid_y)(0.0, 1.5384979288903713)An error of 0 on the training set, and 1.5 on the validation set is bad news! We are overfitting enormously to the training data, and the model doesn’t generalize at all well on the validation set. The reason is that we have almost as many leaf nodes to the tree as there are data points in the training set. This means that we’re being too specific in our predictions, and not leveraging the ability to average across items in a leaf node.
m.get_n_leaves(), len(xs)(950988, 960000)m=DecisionTreeRegressor(min_samples_leaf=50)
m.fit(xs, y)
m_rmse(m, xs, y), m_rmse(m, valid_xs, valid_y)(0.9963146137544396, 1.0883776194426706)That’s better - the model can now generalize to the validation set with an error which is better than just predicting the mean of all the values. 1.2 vs 1.09.
Let’s try a random forest
A random forest trains and ensembles a bunch of decision trees, then takes the average of the predictions from each tree. The main insight here is that because each tree is uncorrelated with each other tree, the errors will also be uncorrelated, and so when we average over all the trees the errors should cancel out.
def rf(xs, y, n_estimators=70, max_samples=200_000,
max_features=0.5, min_samples_leaf=5, **kwargs):
return RandomForestRegressor(n_jobs=-1, n_estimators=n_estimators,
max_samples=max_samples, max_features=max_features,
min_samples_leaf=min_samples_leaf, oob_score=True).fit(xs, y)m=rf(xs, y)m_rmse(m, xs, y), m_rmse(m, valid_xs, valid_y)(0.9449426462779349, 1.0502400634656182)We’re getting a lower error by using a random forest. Increasing the number of estimators does decrease the error on the validation set.
preds = np.stack([t.predict(valid_xs) for t in m.estimators_])/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature names
/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/sklearn/base.py:458: UserWarning: X has feature names, but DecisionTreeRegressor was fitted without feature namesJust to prove that the random forest error is found by taking the average of the predictions of each tree on the validation set…
r_mse(preds.mean(0), valid_y)1.0502400634656182If we add more and more trees, we see that the error on the validation set decreases with diminishing returns past around 40 trees.
p = plt.plot([r_mse(preds[:i+1].mean(0), valid_y) for i in range(70)])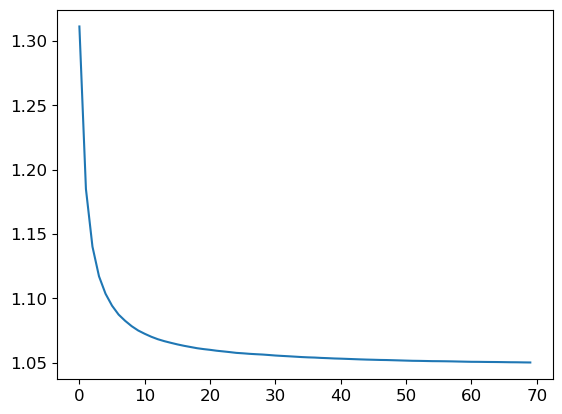
Out of bag error
There’s a small diference in the error between the predictions made on the training set and the predictions made on the validation set. We can check the out of bag error to check whether this difference is due to overfitting, or whether it’s due to the way that the validation set is chosen. The out of bag error measures the error for each estimator on the samples which were not used to train that estimator.
r_mse(m.oob_prediction_, y)1.0515580870790575The out of bag error is the same as the validation set error, meaning that the difference between training and validation set errors is due to the normal generalization error.
Model interpretation
preds.shape(70, 240000)Now we have a prediction for every tree and every row in the validation set (70 trees and 240,000 rows). Using this, we can get the standard deviation of the predictions over all the trees, for each row.
preds_std = preds.std(0)
preds_std[:5]array([0.72445859, 1.27844855, 0.82417322, 0.76324493, 0.69196196])The confidence in predictions varies widely. This is because for some auctions, there is a low standard deviation because the trees agree. For others it is higher, because the trees don’t agree. This information would be useful in a production setting, for example, if the insurance company was deciding what premium to charge a customer, a low confidence prediction might cause them to look more closely at the customer before providing a quote.
Feature importance
It’s not normally enough just to know that a model can make accurate predictions—we also want to know how it’s making predictions. feature importance gives us insight into this. We can get these directly from sklearn’s random forest by looking in the feature_importances_ attribute. Here’s a simple function we can use to pop them into a DataFrame and sort them:
def rf_feature_importance(m, df):
return pd.DataFrame({'cols': df.columns, 'imp': m.feature_importances_}).sort_values('imp', ascending=False)The feature importances of our model show that the most important features are annual income, credit score, and health score. The column ‘id’ should be investigated further - id is just a one to one mapping of the row index, and this shouldn’t be a predictor for the insurance premium - it could be a source of data leakage, or an indication that we need to split the validation set differently in case there is some correlation between the order of the rows and the premium amount. One possible way to fix this is to shuffle and re-index the dataframe before taking the validation split.
fi = rf_feature_importance(m, xs)
fi[:20]| cols | imp | |
|---|---|---|
| 26 | Annual Income | 0.108201 |
| 31 | Credit Score | 0.103677 |
| 28 | Health Score | 0.088151 |
| 24 | id | 0.074412 |
| 39 | Policy Start Elapsed | 0.067989 |
| 25 | Age | 0.054456 |
| 38 | Policy Start Dayofyear | 0.048033 |
| 36 | Policy Start Day | 0.046984 |
| 30 | Vehicle Age | 0.044623 |
| 32 | Insurance Duration | 0.032320 |
| 35 | Policy Start Week | 0.028402 |
| 37 | Policy Start Dayofweek | 0.027716 |
| 6 | Customer Feedback | 0.027060 |
| 29 | Previous Claims | 0.025816 |
| 27 | Number of Dependents | 0.021890 |
| 3 | Occupation | 0.019372 |
| 8 | Exercise Frequency | 0.019217 |
| 2 | Education Level | 0.018937 |
| 1 | Marital Status | 0.018630 |
| 5 | Policy Type | 0.014873 |
df['id'][:5]0 0
1 1
2 2
3 3
4 4
Name: id, dtype: int64A plot of the feature importances shows the relative importances more clearly.
def plot_fi(fi):
return fi.plot('cols', 'imp', 'barh', figsize=(12,7), legend=False)
plot_fi(fi[:40])<Axes: ylabel='cols'>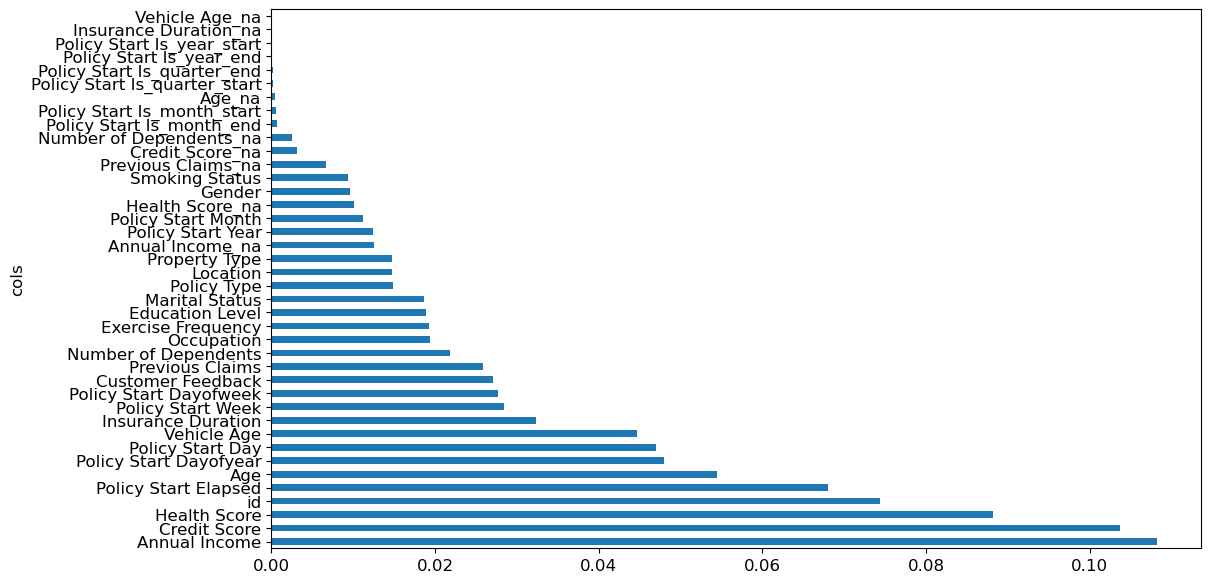
Another possible reason for id being a predictor of premium amount is that the data might be ordered by the time since the policy was taken out- in which case the earlier ids would correlate strongly with the Policy Start Elapsed column. We can check this theory when we investigate redundant features using clustering later on.
The way these importances are calculated is quite simple yet elegant. The feature importance algorithm loops through each tree, and then recursively explores each branch. At each branch, it looks to see what feature was used for that split, and how much the model improves as a result of that split. The improvement (weighted by the number of rows in that group) is added to the importance score for that feature. This is summed across all branches of all trees, and finally the scores are normalized such that they add to 1.
Removing low importance features
It seems likely we could just use a subset of the columns by removing the variables of low importance and still get good results. Let’s just try keeping those with a feature importance greater than 0.005.
to_keep = fi[fi.imp>0.03].cols
len(to_keep)10We can retrain the model with just this subset of important features
xs_imp = xs[to_keep]
valid_xs_imp = valid_xs[to_keep]
m = rf(xs_imp, y)And here’s the result with only 10 columns. The error is slightly higher - a difference of 0.017 - not by much considering we dropped 24 of the 34 columns in the dataset. Training and validation set errors with all 34 columns for reference: (0.945200832139704, 1.0493446526141565)
m_rmse(m, xs_imp, y), m_rmse(m, valid_xs_imp, valid_y)(0.9682381580511055, 1.067670332095297)Since this is entered into a kaggle competition, we’ll squeeze out every last bit of performance we can. 34 columns is already manageable too, so theres not that much to gain by dropping columns.
to_keep = fi[fi.imp>0.005].cols
xs_imp = xs[to_keep]
valid_xs_imp = valid_xs[to_keep]
m = rf(xs_imp, y)
m_rmse(m, xs_imp, y), m_rmse(m, valid_xs_imp, valid_y), len(to_keep)(0.9456035425985689, 1.0495709446069124, 29)plot_fi(rf_feature_importance(m, xs_imp));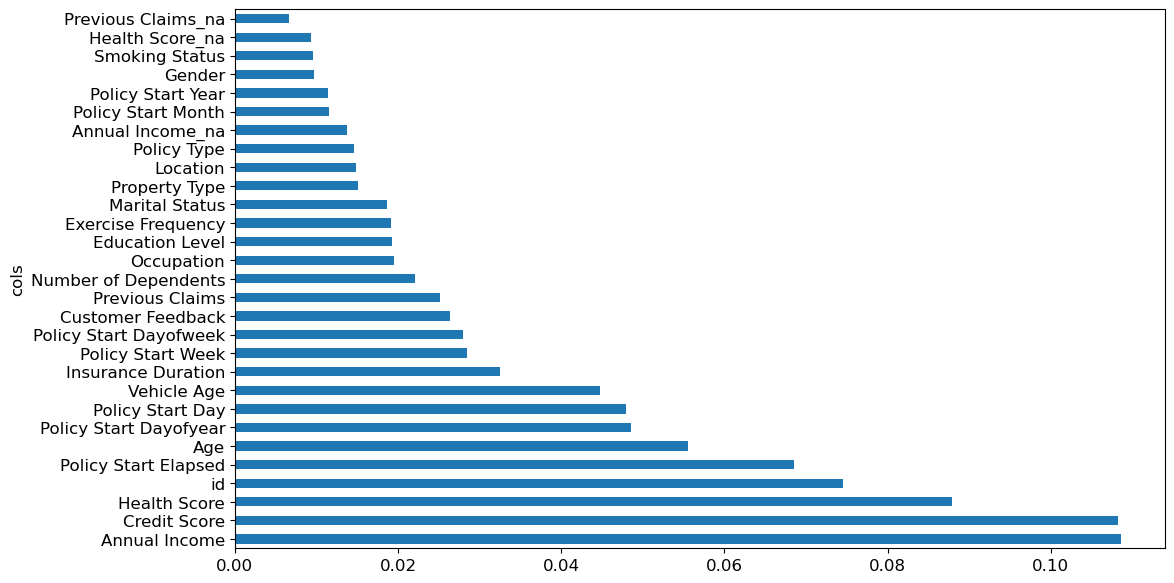
Removing redundant features
cluster_columns(xs_imp)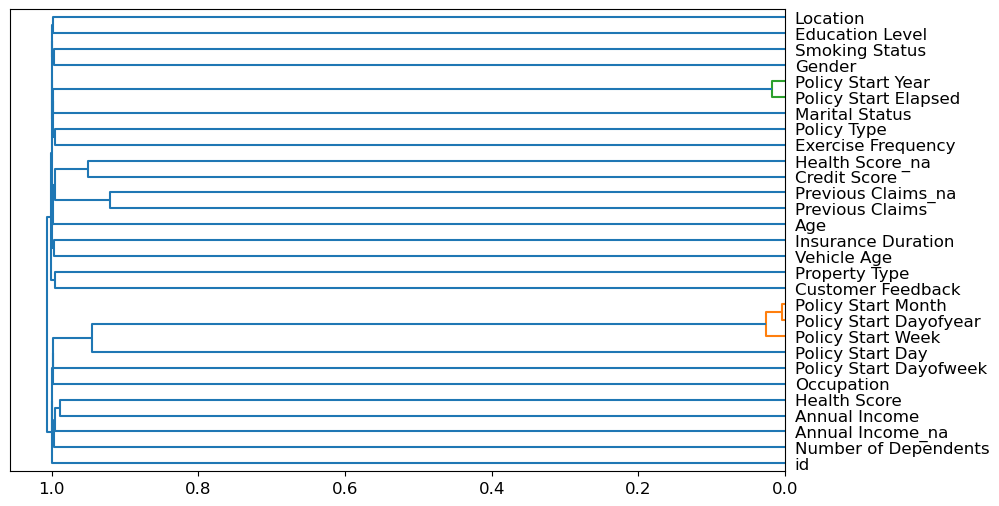
The most closely correlated features are the ones which were merged together early - far from the root of the plot. Policy Start Elapsed and Policy Start Year seem to be the same feature, as do Policy Start Month, Policy Start Dayofyear and Policy Start Day.
Let’s try removing some of these closely correlated features. We’ll make a function to quickly train a random forest and return the OOB score by using fewer max samples and higher min_samples_leaf. The OOB score is the same as R^2 in statistics, where 1.0 is a perfect model and 0.0 represents a random model.
def get_oob(df):
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=15,
max_samples=50000, max_features=0.5, n_jobs=-1, oob_score=True)
m.fit(df, y)
return m.oob_score_Here’s our baseline
get_oob(xs_imp)0.0808873664528722Now try removing the potentially redundant features one at a time. We also noticed that id was a curious feature, so we’ll try to remove that too. And just to show that this technique works, we’ll try removing Health Score which is a relatively important feature.
{c:get_oob(xs_imp.drop(c, axis=1)) for c in ('Policy Start Elapsed', 'Policy Start Year', 'Policy Start Month', 'Policy Start Dayofyear', 'Policy Start Day', 'id', 'Health Score')}{'Policy Start Elapsed': 0.08090314303274648,
'Policy Start Year': 0.08102939644409035,
'Policy Start Month': 0.08080426557153542,
'Policy Start Dayofyear': 0.08068183946105922,
'Policy Start Day': 0.08105194590971565,
'id': 0.08136994865946834,
'Health Score': 0.06938677065103305}Dropping the id column actually improves the model. Let’s try dropping ‘Policy Start Dayofyear’ and ‘Policy Start Day’ and ‘id’ together
to_drop = ['Policy Start Dayofyear', 'Policy Start Day', 'id']
get_oob(xs_imp.drop(to_drop, axis=1))0.08196021477300897It looks as though we can do without those columns.
Let’s create dataframes without those fields and save them.
xs_final = xs_imp.drop(to_drop, axis='columns')
valid_xs_final = valid_xs_imp.drop(to_drop, axis='columns')xs_final.columnsIndex(['Annual Income', 'Credit Score', 'Health Score', 'Policy Start Elapsed',
'Age', 'Vehicle Age', 'Insurance Duration', 'Policy Start Week',
'Policy Start Dayofweek', 'Customer Feedback', 'Previous Claims',
'Number of Dependents', 'Occupation', 'Exercise Frequency',
'Education Level', 'Marital Status', 'Policy Type', 'Location',
'Property Type', 'Annual Income_na', 'Policy Start Year',
'Policy Start Month', 'Health Score_na', 'Gender', 'Smoking Status',
'Previous Claims_na'],
dtype='object')Checkpoint 2
save_pickle(path/'xs_final.pkl', xs_final)
save_pickle(path/'valid_xs_final.pkl', valid_xs_final)
## Checkpoint 2
# xs_final = load_pickle(path/'xs_final.pkl')
# valid_xs_final = load_pickle(path/'valid_xs_final.pkl')We can check the RMSE again to confirm that the accuracy hasn’t changed too much
m = rf(xs_final, y)
m_rmse(m, xs_final, y), m_rmse(m, valid_xs_final, valid_y)(0.948573202959664, 1.049657122485026)We’ve simplified our model by removing unimportant and redundant features and keeping the most important variables, without losing much accuracy. Let’s see how those variables affect our predictions using partial dependence plots.
Partial dependence
We know that the most important features are annual income, credit score and health score. These are all continuous variables. We’d like to understand the relationship between these variables and the premium amount. Let’s check the distribution of these variables and the counts of any continuous variables.
to.classes{'Gender': ['#na#', 'Female', 'Male'],
'Marital Status': ['#na#', 'Divorced', 'Married', 'Single'],
'Education Level': ['#na#', 'High School', "Bachelor's", "Master's", 'PhD'],
'Occupation': ['#na#', 'Employed', 'Self-Employed', 'Unemployed'],
'Location': ['#na#', 'Rural', 'Suburban', 'Urban'],
'Policy Type': ['#na#', 'Basic', 'Comprehensive', 'Premium'],
'Customer Feedback': ['#na#', 'Average', 'Good', 'Poor'],
'Smoking Status': ['#na#', 'No', 'Yes'],
'Exercise Frequency': ['#na#', 'Daily', 'Monthly', 'Rarely', 'Weekly'],
'Property Type': ['#na#', 'Apartment', 'Condo', 'House'],
'Policy Start Is_month_end': ['#na#', False, True],
'Policy Start Is_month_start': ['#na#', False, True],
'Policy Start Is_quarter_end': ['#na#', False, True],
'Policy Start Is_quarter_start': ['#na#', False, True],
'Policy Start Is_year_end': ['#na#', False, True],
'Policy Start Is_year_start': ['#na#', False, True],
'Age_na': ['#na#', False, True],
'Annual Income_na': ['#na#', False, True],
'Number of Dependents_na': ['#na#', False, True],
'Health Score_na': ['#na#', False, True],
'Previous Claims_na': ['#na#', False, True],
'Vehicle Age_na': ['#na#', False, True],
'Credit Score_na': ['#na#', False, True],
'Insurance Duration_na': ['#na#', False, True]}The categorical features aren’t so important in this model, but we can still check the distribution of the value levels for each category if needed:
category = 'Customer Feedback'
p = valid_xs_final[category].value_counts(sort=False, dropna=False).plot.barh()
c = to.classes[category]
print(c)['#na#', 'Average', 'Good', 'Poor']
Check the continuous variables
ax = valid_xs_final['Annual Income'].hist()
ax = valid_xs_final['Credit Score'].hist()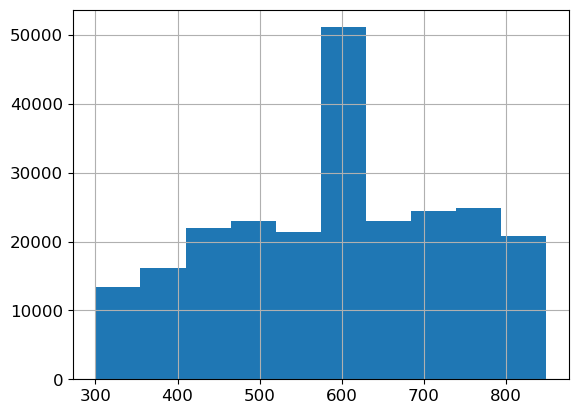
ax = valid_xs_final['Health Score'].hist()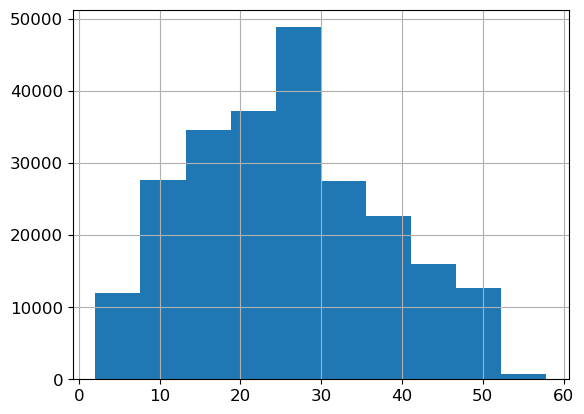
There’s nothing too unusual about these distributions, except that the credit score has a large spike around 600. This could be the default credit score people start out with, or the average credit score for people who had the credit score missing. It’s worth keeping in mind the possibility of data leakage, in case for example the credit score only gets updated with a value after somebody has made a claim, or a similar second order effect.
Partial Dependence Plots
Partial dependence says ‘all other things being equal, what would happen to the predictions if we only varied feature x’
from sklearn.inspection import partial_dependence
from sklearn.inspection import PartialDependenceDisplayPartialDependenceDisplay.from_estimator(m, valid_xs_final, ["Annual Income", "Credit Score", "Health Score"])<sklearn.inspection._plot.partial_dependence.PartialDependenceDisplay at 0x2aba67a00>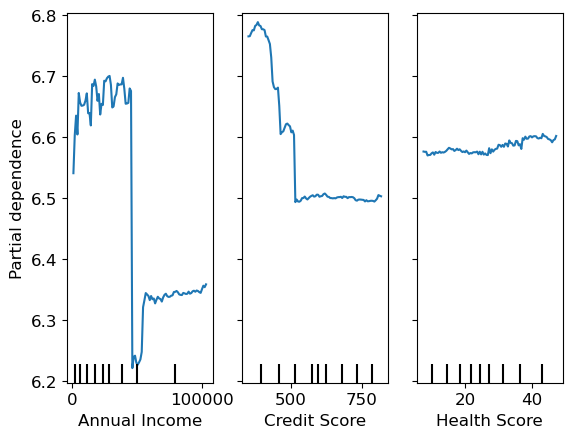
Tree interpreter / Waterfall plots
- For predicting with a particular row of data, what were the most important factors, and how did these influence the prediction?
#hide
import warnings
warnings.simplefilter('ignore', FutureWarning)
from treeinterpreter import treeinterpreter
from waterfall_chart import plot as waterfallChoose the first 5 rows from the dataset
row = valid_xs_final.iloc[:5]prediction,bias,contributions = treeinterpreter.predict(m, row.values)Prediction is the prediction the random forest makes. Bias is the prediction based on taking the mean of the dependent variable - or the average insurance premium for all of the training data point. Contributions is the total change in prediction due to each of the independent variables.
Look at one row from these predictions
idx = 2
prediction[idx], bias[idx], contributions[idx].sum()(array([6.48358116]), 6.594196428003789, -0.11061527134489255)Convert the contribution / error values back up to the original scale
One important thing to remember, is that since these values (and the errors, contributions, biases and the final predictions) are on a logarithmic scale, the contribution change should be measured relative to the bias - not relative to zero. For example, if we just take np.expm1(0.11) we might be led to think that the model only predicted a change of 10 cents. To get an idea of how much the final price was affected, we should be calculating the change relative to the bias:
np.expm1(bias) - np.expm1(bias + contributions)np.expm1(bias[idx]) - np.expm1(bias[idx] + contributions[idx].sum())76.53142498631871For this row, we can see the total contribution changes which each column makes to the prediction, measured relative to the baseline bias - or average premium over the whole dataset.
waterfall(valid_xs_final.columns, contributions[idx], threshold=0.08,
rotation_value=90,formatting='{:,.3f}');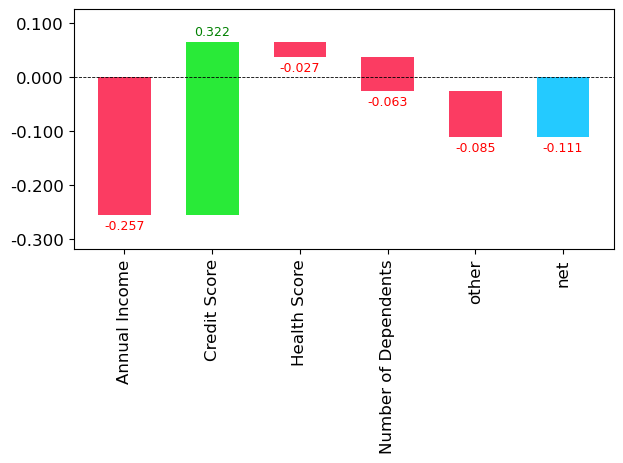
feature = "Annual Income"
pd.DataFrame(valid_xs_final.iloc[2]).T[feature], valid_xs_final[feature].mean()(893682 51164.0
Name: Annual Income, dtype: float32,
32426.771)np.expm1(bias[idx]) - np.expm1(bias[idx] + 0.257)-214.16950103598538Having an annual income of 20k above the mean value of 32k increases the premium by $214.
For this example, we can see that Annual Income reduced the premium amount by 0.257 but the relatively low credit score increases the premium back up by 0.322. The real world change here is:
np.expm1(bias[idx]) - np.expm1(bias[idx] + 0.322)-277.6355089663125Let’s find the largest possible contribution from income
# find the row with the maximum Annual Income from valid_xs_final
max_income = pd.DataFrame(valid_xs_final.loc[valid_xs_final['Annual Income'].idxmax()]).T
max_income| Annual Income | Credit Score | Health Score | Policy Start Elapsed | ... | Health Score_na | Gender | Smoking Status | Previous Claims_na | |
|---|---|---|---|---|---|---|---|---|---|
| 810763 | 149996.0 | 637.0 | 28.988052 | 1.715354e+09 | ... | 1.0 | 2.0 | 2.0 | 1.0 |
1 rows × 26 columns
prediction,bias,contributions = treeinterpreter.predict(m, max_income.values)
prediction, bias, contributions.sum()(array([[5.27780681]]), array([6.59419643]), -1.3163896198702738)waterfall(valid_xs_final.columns, contributions[0], threshold=0.08,
rotation_value=90,formatting='{:,.3f}');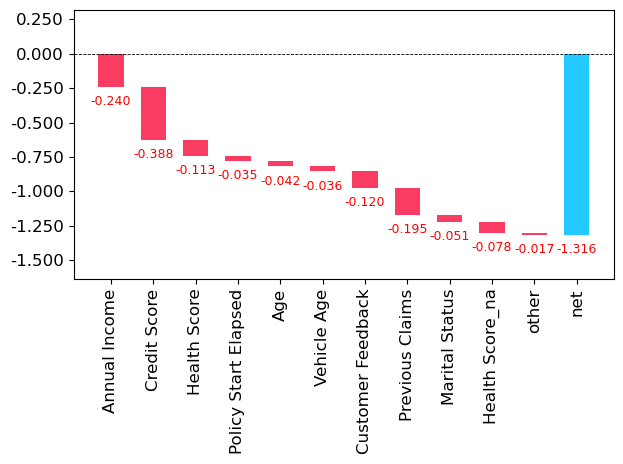
np.expm1(bias) - np.expm1(prediction)array([[534.90169654]])The highest earner in the dataset gets a reduction in premium of $535
One interesting observation here, is that income seems to be a proxy for a bunch of other predictive variables.
Making a prediction
To make predictions on the test set, we need to load the test set into Pandas then preprocess it in the same way as the test set was processed.
# Test df
tdf = pd.read_csv('test.csv')tdf.columnsIndex(['id', 'Age', 'Gender', 'Annual Income', 'Marital Status',
'Number of Dependents', 'Education Level', 'Occupation', 'Health Score',
'Location', 'Policy Type', 'Previous Claims', 'Vehicle Age',
'Credit Score', 'Insurance Duration', 'Policy Start Date',
'Customer Feedback', 'Smoking Status', 'Exercise Frequency',
'Property Type'],
dtype='object')tdf["Education Level"] = tdf['Education Level'].astype('category')
tdf["Education Level"] = tdf['Education Level'].cat.set_categories(edu_levels, ordered=True)
tdf = add_datepart(tdf, 'Policy Start Date')
# Test tabular object
tto = TabularPandas(tdf, procs, cat, cont)
# m.predict(df_test)/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:25: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.tto.show(3)| Gender | Marital Status | Education Level | Occupation | Location | Policy Type | Customer Feedback | Smoking Status | Exercise Frequency | Property Type | Policy Start Is_month_end | Policy Start Is_month_start | Policy Start Is_quarter_end | Policy Start Is_quarter_start | Policy Start Is_year_end | Policy Start Is_year_start | Age_na | Annual Income_na | Number of Dependents_na | Health Score_na | Previous Claims_na | Vehicle Age_na | Credit Score_na | Insurance Duration_na | id | Age | Annual Income | Number of Dependents | Health Score | Previous Claims | Vehicle Age | Credit Score | Insurance Duration | Policy Start Year | Policy Start Month | Policy Start Week | Policy Start Day | Policy Start Dayofweek | Policy Start Dayofyear | Policy Start Elapsed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Female | #na# | Bachelor's | Self-Employed | Rural | Basic | Poor | Yes | Weekly | House | False | False | False | False | False | False | False | False | False | False | True | False | True | False | 1200000 | 28.0 | 2310.0 | 4.0 | 7.657981 | 1.0 | 19.0 | 595.0 | 1.0 | 2023 | 6 | 22 | 4 | 6 | 155 | 1.685892e+09 |
| 1 | Female | Married | Master's | Self-Employed | Suburban | Premium | Good | Yes | Rarely | Apartment | False | False | False | False | False | False | False | False | False | False | True | False | False | False | 1200001 | 31.0 | 126031.0 | 2.0 | 13.381379 | 1.0 | 14.0 | 372.0 | 8.0 | 2024 | 4 | 17 | 22 | 0 | 113 | 1.713799e+09 |
| 2 | Female | Divorced | PhD | Unemployed | Urban | Comprehensive | Average | Yes | Monthly | Condo | False | False | False | False | False | False | False | False | False | False | True | False | False | False | 1200002 | 47.0 | 17092.0 | 0.0 | 24.354527 | 1.0 | 16.0 | 819.0 | 9.0 | 2023 | 4 | 14 | 5 | 2 | 95 | 1.680708e+09 |
# Test xs
txs = tto.xsto_keep26 Annual Income
31 Credit Score
28 Health Score
24 id
39 Policy Start Elapsed
...
34 Policy Start Month
19 Health Score_na
0 Gender
7 Smoking Status
20 Previous Claims_na
Name: cols, Length: 29, dtype: objecttxs_imp = txs[to_keep]txs_final = txs_imp.drop(to_drop, axis='columns')submission = m.predict(txs_final)# write submission to a csv file with headers id,Premium Amount
submission_df = pd.DataFrame({'id': tdf['id'], 'Premium Amount': np.expm1(submission)})submission_df.to_csv('submission.csv', index=False)submission_df.head()| id | Premium Amount | |
|---|---|---|
| 0 | 1200000 | 801.737461 |
| 1 | 1200001 | 853.567610 |
| 2 | 1200002 | 743.969326 |
| 3 | 1200003 | 814.828909 |
| 4 | 1200004 | 653.490348 |
Using this approach resulted in a model which placed 818/2392 on the Kaggle private leaderboard.
That’s 35th percentile. In general if you place above the 50th percentile on Kaggle you’ve done pretty well and have a model which would perform well in production. This is because the competitive nature of the Kaggle competitions incentivise entries with more and more marginal gains.
Improving on the Random Forest.
The extrapolation problem
TL;DR: Random forests can’t extrapolate beyond the range of the training data.
# Synthetic linear data with noise
x_lin = torch.linspace(0, 20, steps=40)
y_lin = x_lin + torch.randn_like(x_lin)
plt.scatter(x_lin, y_lin)<matplotlib.collections.PathCollection at 0x2aac4a560>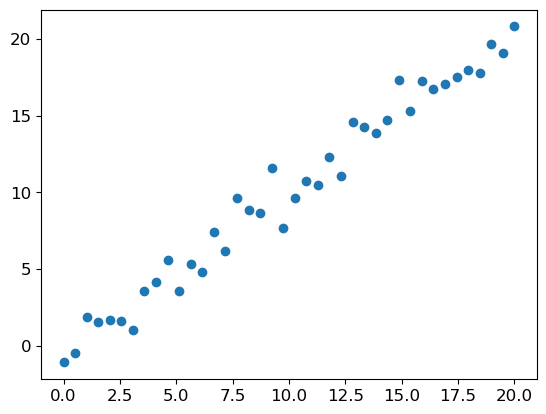
x_lin.shapetorch.Size([40])sklearn expects a matrix of independent variables, not a single vector. We can use unsqueeze(1) or slice the array to a tensor with the special value None:
xs_lin = x_lin[:, None]
xs_lin.shapetorch.Size([40, 1])Let’s train a random forest on the first 30 data points and leave the final 10 out.
m_lin = RandomForestRegressor().fit(xs_lin[:30], y_lin[:30])plt.scatter(x_lin, y_lin)
plt.scatter(x_lin, m_lin.predict(xs_lin), color='red', alpha=0.5)<matplotlib.collections.PathCollection at 0x2b2397e50>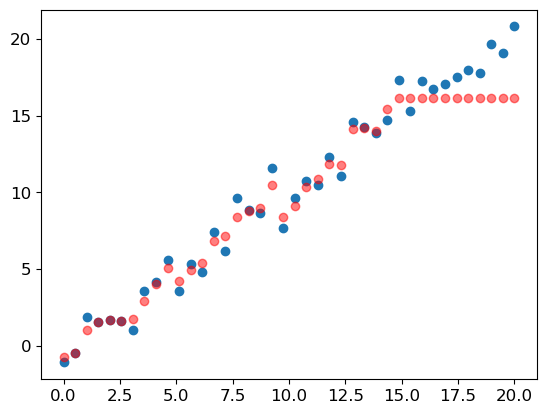
This demonstration shows how random forests can’t extrapolate beyond the range of the training data. If there’s a time series component, such as inflation, or just some new ranges which didn’t occur in the training set, then the random forest will not be able to predict accurately for these cases and the predictions will be systematically too low or too high.
Finding out-of-domain data
To find out whether the training set and the validation set are distributed in the same way, we can use a cool trick and train a random forest to predict whether a row of data is from the training set or the validation set!
# df out-of-domain
df_dom = pd.concat([xs_final, valid_xs_final])
is_valid = np.array([0]*len(xs_final) + [1]*len(valid_xs_final))
m = rf(df_dom, is_valid)
rf_feature_importance(m, df_dom)[:12]| cols | imp | |
|---|---|---|
| 0 | Annual Income | 0.114124 |
| 2 | Health Score | 0.113457 |
| 1 | Credit Score | 0.098175 |
| 3 | Policy Start Elapsed | 0.094904 |
| 4 | Age | 0.076022 |
| 5 | Vehicle Age | 0.060459 |
| 7 | Policy Start Week | 0.058718 |
| 6 | Insurance Duration | 0.042909 |
| 8 | Policy Start Dayofweek | 0.037940 |
| 11 | Number of Dependents | 0.029121 |
| 12 | Occupation | 0.026123 |
| 14 | Education Level | 0.025980 |
Since these columns are all predictors of whether a row is from the training set or the validation set, they are the features which contain the highest differences in distribution. In our case, we just took a random sample of the data, so there’s not much we can do to help here. But in cases where there is a temporal or other necessary split, it would be helpful to remove those columns for which there is a large difference in distribution, and which don’t contribute too much to the accuracy of the model.
m = rf (xs_final, y)
print('orig', m_rmse(m, valid_xs_final, valid_y))
for c in ("Annual Income", "Health Score", "Credit Score", "Policy Start Elapsed", "Age", "Vehicle Age", "Policy Start Week"):
m = rf(xs_final.drop(c, axis=1), y)
print(c, m_rmse(m, valid_xs_final.drop(c, axis=1), valid_y))orig 1.0491192462331866
Annual Income 1.0870869717827008
Health Score 1.0560707798218818
Credit Score 1.080604905922193
Policy Start Elapsed 1.0488449446368762
Age 1.049118477547121
Vehicle Age 1.0491874480475374
Policy Start Week 1.0488886655687548It looks as though we should be able to remove the columns ‘Policy Start Week’, ‘Policy Start Elapsed’, and ‘Age’ without losing too much accuracy.
bias_vars = ['Policy Start Week', 'Policy Start Elapsed', 'Age']
xs_final_bias = xs_final.drop(bias_vars, axis=1)
valid_xs_bias = valid_xs_final.drop(bias_vars, axis=1)
m = rf(xs_final_bias, y)
m_rmse(m, valid_xs_bias, valid_y)1.0488895553861335Removing the columns which were biased
Retraining the model without those bias columns gives slightly better accuracy, but more importantly it should make the model more resillient, easier to maintain and understand.
Again, this would be especially important for datasets where the training and validation sets were split by time or some other necessary split..
This approach can be used on any dataset to detect subtle domain shift issues which otherwise might not be noticed.
Removing old data
Sometimes the older data contains relationships which are no longer valid. Removing rows from before a certain year can often improve performance, and shows that you shouldn’t always use all of the available data. Sometimes a well chosen subset is better.
Neural Networks
df_nn = pd.read_csv(path/"train.csv", low_memory=False)
df_nn["Education Level"] = df_nn['Education Level'].astype('category')
df_nn["Education Level"] = df_nn['Education Level'].cat.set_categories(edu_levels, ordered=True)
df_nn[dep_var] = np.log1p(df_nn[dep_var])
df_nn = add_datepart(df_nn, 'Policy Start Date')/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:25: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.drop = ['Annual Income_na', 'Health Score_na', 'Previous Claims_na']df_nn_final = df_nn[list(xs_final_bias.drop(columns=drop).columns) + [dep_var]]cont_nn, cat_nn = cont_cat_split(df_nn_final, max_card=9000, dep_var=dep_var)cont_nn, cat_nn(['Annual Income',
'Credit Score',
'Health Score',
'Vehicle Age',
'Insurance Duration',
'Previous Claims',
'Number of Dependents'],
['Policy Start Dayofweek',
'Customer Feedback',
'Occupation',
'Exercise Frequency',
'Education Level',
'Marital Status',
'Policy Type',
'Location',
'Property Type',
'Policy Start Year',
'Policy Start Month',
'Gender',
'Smoking Status'])cont_nn.append('Policy Start Year')
cont_nn.remove('Policy Start Year')df_nn_final[cat_nn].nunique()Policy Start Dayofweek 7
Customer Feedback 3
Occupation 3
Exercise Frequency 4
Education Level 4
Marital Status 3
Policy Type 3
Location 3
Property Type 3
Policy Start Year 6
Policy Start Month 12
Gender 2
Smoking Status 2
dtype: int64There aren’t many high cardinality categorical variables in this dataset.
procs_nn = [Categorify, FillMissing, Normalize]
to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn, splits=splits, y_names=dep_var)dls = to_nn.dataloaders(1024)y = to_nn.train.y
y.min(), y.max()(3.0445225, 8.516793)class RMSLELoss(nn.Module):
def __init__(self):
super().__init__()
self.mse = nn.MSELoss()
def forward(self, pred, actual):
return torch.sqrt(self.mse(torch.log1p(pred), torch.log1p(actual)))
custom_rmsle_loss = RMSLELoss()from fastai.tabular.all import *
learn = tabular_learner(dls, y_range=(3, 9),layers=[200,100], n_out=1, loss_func=custom_rmsle_loss)
learn.lr_find()SuggestedLRs(valley=0.0008317637839354575)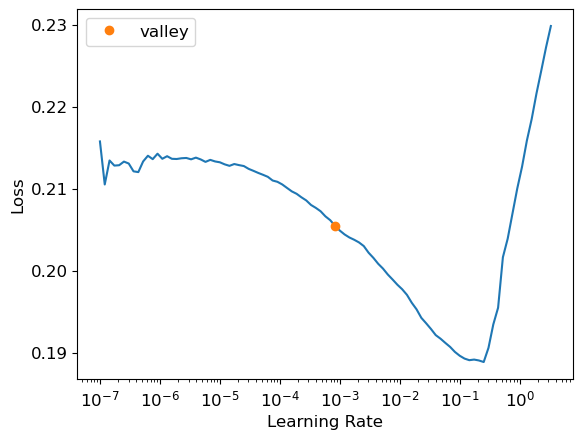
learn.fit_one_cycle(5, 1e-2)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.163907 | 0.166388 | 00:25 |
| 1 | 0.162703 | 0.165677 | 00:24 |
| 2 | 0.163396 | 0.163910 | 00:24 |
| 3 | 0.163030 | 0.163344 | 00:24 |
| 4 | 0.161707 | 0.163257 | 00:24 |
preds, targs = learn.get_preds()
r_mse(preds, targs)1.087911609056907learn.modelTabularModel(
(embeds): ModuleList(
(0): Embedding(8, 5)
(1-2): 2 x Embedding(4, 3)
(3-4): 2 x Embedding(5, 4)
(5-8): 4 x Embedding(4, 3)
(9): Embedding(7, 5)
(10): Embedding(13, 7)
(11-19): 9 x Embedding(3, 3)
)
(emb_drop): Dropout(p=0.0, inplace=False)
(bn_cont): BatchNorm1d(7, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layers): Sequential(
(0): LinBnDrop(
(0): Linear(in_features=77, out_features=200, bias=False)
(1): ReLU(inplace=True)
(2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): LinBnDrop(
(0): Linear(in_features=200, out_features=100, bias=False)
(1): ReLU(inplace=True)
(2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): LinBnDrop(
(0): Linear(in_features=100, out_features=1, bias=True)
)
(3): fastai.layers.SigmoidRange(low=3, high=9)
)
)learn = tabular_learner(dls, y_range=(3,9), layers=[500,250], n_out=1, loss_func=custom_rmsle_loss)
learn.lr_find()SuggestedLRs(valley=0.0002290867705596611)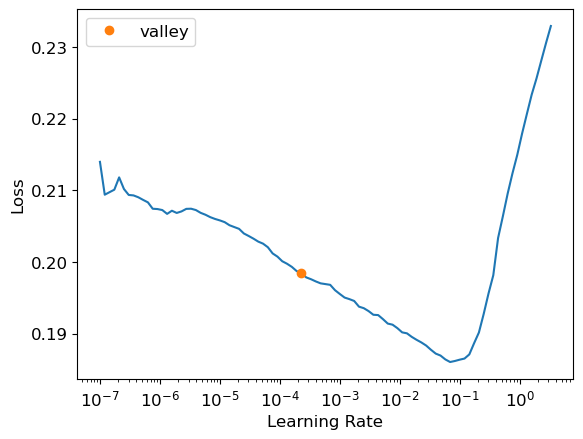
learn.fit_one_cycle(10, 1e-2)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.162351 | 0.164317 | 00:24 |
| 1 | 0.159144 | 0.160406 | 00:24 |
| 2 | 0.159710 | 0.159286 | 00:24 |
| 3 | 0.158863 | 0.158587 | 00:25 |
| 4 | 0.158756 | 0.158806 | 00:24 |
| 5 | 0.158931 | 0.158449 | 00:24 |
| 6 | 0.157816 | 0.158194 | 00:24 |
| 7 | 0.158522 | 0.158232 | 00:24 |
| 8 | 0.157851 | 0.157965 | 00:24 |
| 9 | 0.157388 | 0.158006 | 00:24 |
learn.recorder.plot_loss()<Axes: title={'center': 'learning curve'}, xlabel='steps', ylabel='loss'>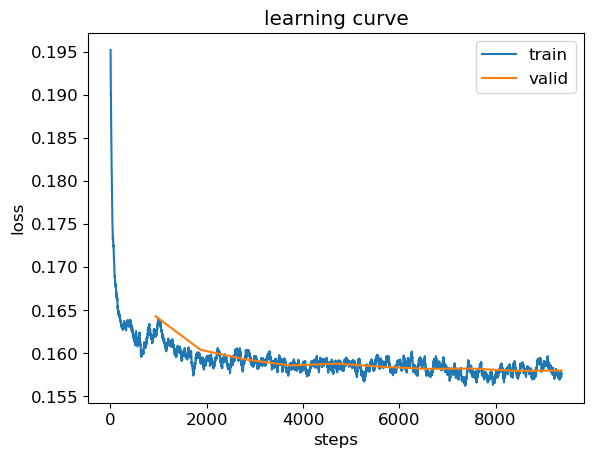
preds, targs = learn.get_preds()
r_mse(preds, targs)1.05219380897146441.04888 is the score to beat from the random forest. One more attempt - the training curve is pretty noisy. Let’s reduce the learning rate a bit to see if we can get a better result.
learn.fit_one_cycle(5, 1e-4)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.158851 | 0.158034 | 00:25 |
| 1 | 0.157593 | 0.157959 | 00:25 |
| 2 | 0.157541 | 0.157977 | 00:24 |
| 3 | 0.158346 | 0.158004 | 00:25 |
| 4 | 0.157386 | 0.157996 | 00:25 |
preds, targs = learn.get_preds()
r_mse(preds, targs)1.0521918829386747The neural network didn’t work as well as the random forest for this dataset. It may perform better on other datasets where extrapolation is needed.
learn.save('nn')Path('models/nn.pth')Ensembling
rf_preds = m.predict(valid_xs_bias)
preds, rf_preds(tensor([[6.6099],
[6.1475],
[6.5474],
...,
[6.5842],
[6.3467],
[6.6124]]),
array([6.55583468, 6.42468671, 6.73674726, ..., 6.604843 , 6.66766988, 6.63748909]))The predictions from the neural net and from the random forest are different data types. PyTorch gives us a rank 2 tensor, whereas sklearn gives us a vector, or a rank 1 array.
ens_preds = (to_np(preds.squeeze()) + rf_preds) / 2r_mse(ens_preds, valid_y)1.0475928203186846Ensembling the two models together gives a better result than either model achieved on its own.
Submit the ensemble preds to Kaggle
rf_submission = m.predict(txs_final.drop(bias_vars, axis=1))Process the test set for NN
- Load the test set,
- scale the data and drop some columns,
- Normalize the data since it’s going into a neural network.
test_nn = pd.read_csv(path/"test.csv", low_memory=False)
test_nn["Education Level"] = test_nn['Education Level'].astype('category')
test_nn["Education Level"] = test_nn['Education Level'].cat.set_categories(edu_levels, ordered=True)
test_nn[dep_var] = np.log1p(df_nn[dep_var])
test_nn = add_datepart(test_nn, 'Policy Start Date')/Users/mikeg/miniforge3/envs/fastai/lib/python3.10/site-packages/fastai/tabular/core.py:25: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.test_nn_final = test_nn[list(xs_final_bias.drop(columns=drop).columns)]procs_test_nn = [Categorify, FillMissing, Normalize]
to_test_nn = TabularPandas(test_nn_final, procs_nn, cat_nn, cont_nn)
type(to_test_nn)fastai.tabular.core.TabularPandasdls.test_dl(to_test_nn.items)<fastai.tabular.core.TabWeightedDL at 0x2d1c16230>Make predictions on the test set using the neural network
nn_test_preds, _ = learn.get_preds(dl=dls.test_dl(to_test_nn.items))
nn_test_preds[:5]tensor([[6.6865],
[6.7124],
[6.7418],
[6.6907],
[6.7238]])ensemble_submission = (to_np(nn_test_preds.squeeze()) + rf_submission) / 2# write submission to a csv file with headers id,Premium Amount
submission_df = pd.DataFrame({'id': test_nn['id'], 'Premium Amount': np.expm1(ensemble_submission)})submission_df.to_csv('ensemble_submission.csv', index=False)submission_df.head()| id | Premium Amount | |
|---|---|---|
| 0 | 1200000 | 722.564827 |
| 1 | 1200001 | 796.460073 |
| 2 | 1200002 | 733.961725 |
| 3 | 1200003 | 838.133342 |
| 4 | 1200004 | 826.356850 |