Solving linear and nonlinear equations with neural networks
Universal Approximation Theorem
PyTorch
Feature Crosses
Neural Networks
Linear Equations
Nonlinear Equations
Published
February 1, 2023
Exploring the capability of neural networks to solve simple linear and nonlinear algebraic equations.
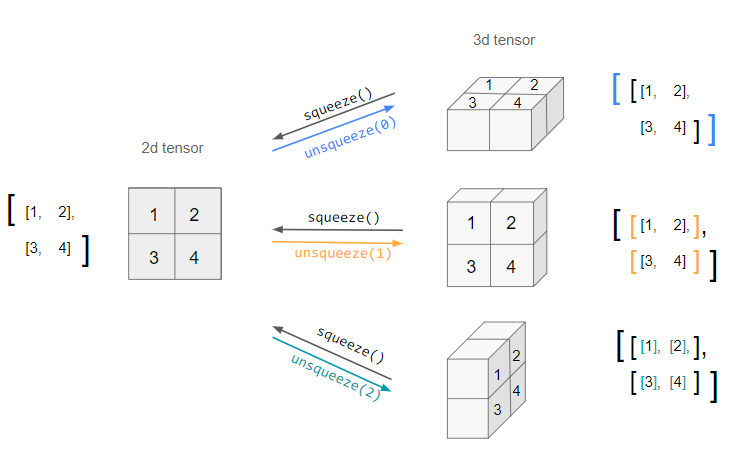
squeeze
Topics covered: - PyTorch - Feature Crosses - Linear and nonlinear models - universal approximation theorem - interpreting loss curves
In this example, I asked chat GPT to generate a PyTorch training loop for a linear model, from a synthetic dataset. The code produced was great. It gave me ideas and some framework code from which to develop my own understanding. Modifying and developing the code was a quick way to explore some new functions and explore some ideas in an interactive way.
I wanted to get an intuitive understanding of the universal approximation theorem, in order to be able to better decide when to choose a neural network, and when to choose another type of model.
Part 1: using the original solution from Chat GPT
Here’s the original code which was returned by GPT3.
This code will run, but the model won’t reach an optimal solution with only 10 epochs to train.
In the rest of the notebook I modified this code to provide graphs of the loss over time, and convert this linear model into a higher order model.
import torchimport matplotlib.pyplot as pltfrom torch.utils.data import TensorDataset, DataLoader# Generate a synthetic datasetX = torch.randn(100, 10)y =2* X[:, 0] -3* X[:, 1] +1dataset = TensorDataset(X, y)# Define the modelmodel = torch.nn.Linear(10, 1)# Define the loss functionloss_fn = torch.nn.MSELoss()# Define the optimizeroptimizer = torch.optim.SGD(model.parameters(), lr=0.01)# Define the data loaderloader = DataLoader(dataset, batch_size=16, shuffle=True)# Train the modelfor epoch inrange(10):for batch_X, batch_y in loader:# Zero the gradients optimizer.zero_grad()# Compute the model's predictions preds = model(batch_X)# Compute the loss loss = loss_fn(preds.squeeze(), batch_y)# Backpropagate the gradients loss.backward()# Update the weights optimizer.step()print(f"Epoch {epoch}: loss={loss.item()}")# Evaluate the model on a test settest_X = torch.randn(10, 10)test_y =2* test_X[:, 0] -3* test_X[:, 1] +1test_preds = model(test_X)test_loss = loss_fn(test_preds.squeeze(), test_y)print(f"Test loss: {test_loss.item()}")
We can see that the loss decreases consistently. Training the model for longer will provide more chance to converge. We can plot the loss per epoch to see how the trianing process behaves.
The input X has the shape 100 x 10, so there are 100 rows and 10 columns in the input features X.
We can call each column of X a different feature, each feature is available to the model. So the first column is X0 and the second column is X1 etc
The only features which have an effect on the dependent variable y are the first two columns. The remaining 8 columns are just random number arrays, but they’re still included as inputs to the model.
The relation between the independent variable X and the dependent variable y is:
\(y=2X_0-3X_1+1\)
So after sufficient training, the model should converge towards a set of parameters where the first two values are 2, -3, and the rest of the parameters are zero. The bias should be 1.
Here’s a modified training loop which keeps a record of the loss per epoch
We can reset the model parameters by trying out PyTorch’s reset_parameters() method. First let’s make sure the method works. Here’s a great stackoverflow post about initializing weights in pytorch - check out ashunigion’s answer to get an idea for good initial values for the model parameter (tldr: make the parameters between -y and y where y is \(1\div{sqrt(n)}\) and n is the number of inputs to a given neuron.
The parameters have been randomized again. They seem to lie between about -0.3 and 0.3, which is good. We want the parameters to be small but not too close to zero.
Then re-train the model for more epochs and print the loss curves.
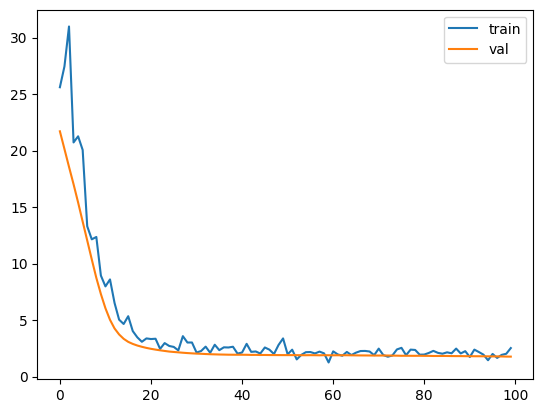
# Train the modelepochs =100train_losses = []validation_losses = []for epoch inrange(epochs):for batch_X, batch_y in loader:# Zero the gradients optimizer.zero_grad()# Compute the model's predictions preds = model(batch_X)# Compute the loss loss = loss_fn(preds.squeeze(), batch_y)# Backpropagate the gradients loss.backward()# Update the weights optimizer.step() train_losses.append(loss.item())# Evaluate the model on a test set test_X = torch.randn(10, 10) test_y =2* test_X[:, 0] -3* test_X[:, 1] +1 test_preds = model(test_X) test_loss = loss_fn(test_preds.squeeze(), test_y) validation_losses.append(test_loss.item())if (epoch+1) %10==0:print(f"Epoch {epoch}: loss={loss.item()}")plt.plot(range(epochs), train_losses, label='train')plt.plot(range(epochs), validation_losses, label='val')plt.legend()
Great! We can see that the model converges towards the optimal solution for this linear input.
We’re looking for
$w_0 = 2 $ \(w_1 = -3\) \(b = 1\)
and the parameters of the model are pretty close.
We were able to generate a new validation set each epoch - since we’re using a synthetic dataset. In real life we’d have taken a sample from the training data and use this for validation.
Part 2: Let’s use this code to train a different type of model.
In this example the dependent varaible is calculated using the product of \(X_0\) and \(X_1\)
Equations
In this section, the dependent variable y is again a function of the independent variable X, but it is calculated using the product of \(X_0\) and \(X_1\)
\(y = (2X_0-3)(X_1 + 1)\)
Expanding the brackets gives
\(y=2X_0X_1 + 2X_0 -3X_1 - 3\)
Generate a synthetic dataset with the new dependent variable
In this example the dependent varaible is proportional to the product \(X_0\) and \(X_1\) At first this won’t be available to our linear model, and we’ll see what effect this has on the model’s ability to converge towards optimal values for the weights and biases.
The dataset contains pairs of input features and labels stored as an iterable of tuples.
The DataLoader object loader returns batches of examples from the dataset.
# Define the data loaderloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
The training set x has the shape 800 x 10, so there are 800 rows and 10 columns for this feature matrix.
We can call each column of x a different feature. Each feature is seen by the model. So the first item is x0 and the second feature is x1 etc
The only features which have an effect on the dependent variable y are the first two columns. The remaining 8 columns are just random number arrays, but they’re still inputted to the model.
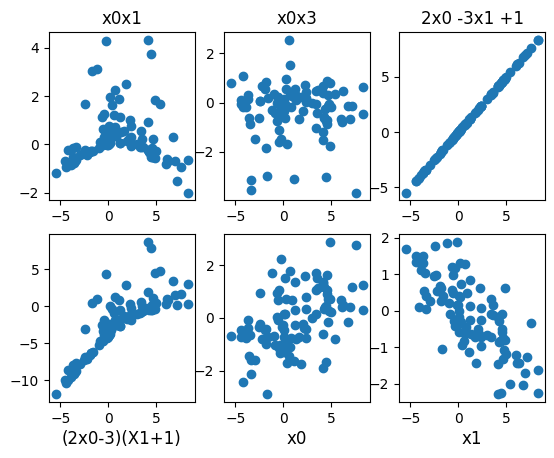
We can make plots to see which features have an effect on the dependent variable y.
As expected, plotting y against various combinations of X1 and X2 reveals correlation between the variables.
Including other variables such as X3 and X8 makes a noisy plot, because these features are just random numbers which have no bearing on y.
The line y=x is shown in the 4th image. The 2nd and 3rd images show random distributions and the rest of them show correlation of some sort. The relation between y and x in the last two plots doesn’t appear to be a linear one.
So the job of our linear model will be to optimize the weights and bias to pick out the relevant columns from X, and to find the coefficients of these columns which best map to y.
From the equations above we know that the coefficients are - w=2 and for feature X[:, 0]
and - w=-3, for feature X[:, 1]
and the bias should be -3
Additionally y is proportional to \(X_0X_1\)
Run the same linear model on this new data
# Define the modelmodel = torch.nn.Linear(10, 1)
The model describes a linear transformation of 10 input features into one output feature. It multiplies each input feature by a different coefficient, adds a bias to them all, and returns one output. This one output will be calculated for each of the 1000 rows in X.
The feature X is defined as X = torch.randn(1000, 10)
This means there are 1000 examples, each of which has 10 features.
Here are the 10 randomly initialised parameters of the model - before any training has been done.
Setting custom weights is possible by passing in a tensor of weights into model.weights.data. The tensor has to be a matrix so we pass in a dimension of length 10 and a second dimension of length 1.
It can also be done by using the zero_ inplace method.
This is only shown as an example - random initialization is probably a safer place to begin training.
# Define the loss functionloss_fn = torch.nn.MSELoss()
# Define the optimizeroptimizer = torch.optim.SGD(model.parameters(), lr=0.001)
Training Loop
Make a general training loop for the rest of the experiments
For each training loop, we’ll need to input a loader object to load items from the training data, a model, and specify the number of epochs the model should train for.
Additionally we’ll split the data into validation and training set rather than generating a new set of test data each epoch.
def train(epochs, loader, model, val_x, val_y, print_losses=False): for layer in model.children():ifhasattr(layer, 'reset_parameters'): layer.reset_parameters() epochs = epochs train_losses = [] validation_losses = []for epoch inrange(epochs):for batch_X, batch_y in loader:# Zero the gradients optimizer.zero_grad()# Compute the model's predictions preds = model(batch_X)# Compute the loss loss = loss_fn(preds.squeeze(), batch_y)# Backpropagate the gradients loss.backward()# Update the weights optimizer.step() train_losses.append(loss.item())# Evaluate the model on the validation set val_preds = model(val_x) val_loss = loss_fn(val_preds.squeeze(), val_y) validation_losses.append(val_loss.item())if (epoch+1) %10==0and print_losses:print(f"Epoch {epoch}: losses={[loss.item(), val_loss.item()]}") plt.plot(range(epochs), train_losses, label='train') plt.plot(range(epochs), validation_losses, label='val') plt.legend()print(f'{loss.item():.3f}, {val_loss.item():.3f}')
Remember we defined the dependent variable as \(y=2X_0X_1 + 2X_0 -3X_1 - 3\)
It looks as though the model has been able to get close to the correct coefficients for \(X_0\) and \(X_1\)
The fact that the model is able to optimize the coefficients for the linear portion of this problem despite the noise, is pretty cool I think!
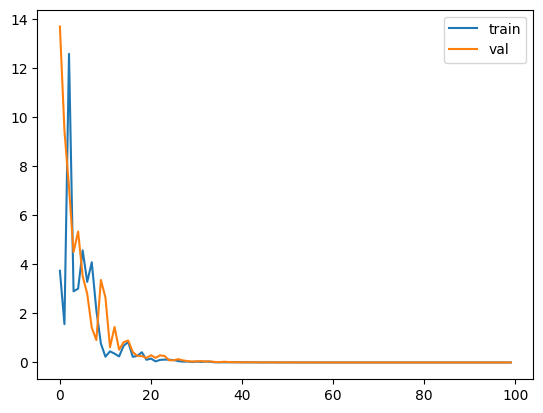
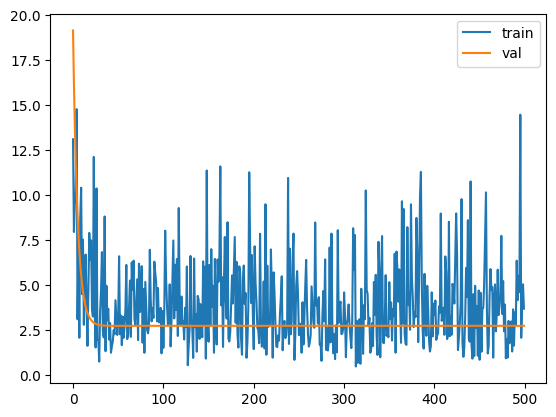
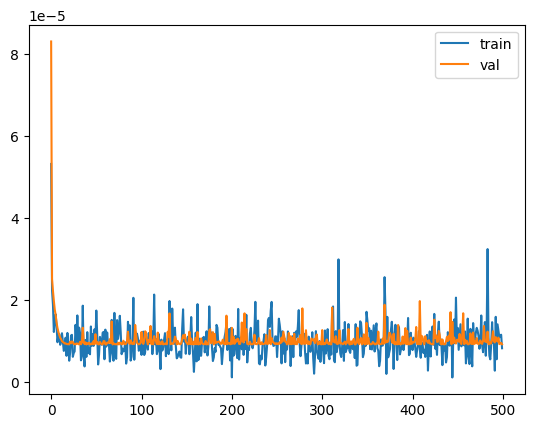
But the model is unstable and the loss curve on the tranining set is noisy - and the validation loss never approaches zero. After running for 500 epochs, there’s still a lot of noise and the validation loss is settled at around 5. This is to be expected since the model doesn’t have a way of representing one of the input features \(X_0*X_1\). It has found the best linear solution to theis problem given the shape of the model.
Noise in the training loss curve
Each epoch, a new random subset from the training set is picked. Calculating the loss against this new random subset each epoch reveals a different error- sometimes by chance the error is lower, and sometimes it is higher. This is the source of the noise in the training loss curve.
Clean validation loss curve which doesn’t reach zero
The loss is
Providing the model with access to the missing feature.
We have two options here - we can either make the model more complex and give it an extra layer of neurons, or we can do some feature engineering and provide \(X_0X_1\) as one of the input features to our linear model.
The first approach I will try is feature engineering.
Feature Crosses
Allow a linear model to represent nonlinearities, by providing higher order features as input.
For example, consider a linear model which maps input x to output y. We can make this model represent $ y=x^2 $ by providing \(x^2\) as the input, instead of x. The model itself will still do a linear mapping, but we’ve done some engineering of the feature inputs.
If we want to keep our model as a linear model, we need to do some feature engineering. We know that providing access to the product of the first and second X columns is all we need. Let’s test to see if this works.
Calculate the new feature
product = X[:, 0]*X[:,1]product.shape
torch.Size([1000])
product = product.unsqueeze(1)product.shape
torch.Size([1000, 1])
What does unsqueeze do?
PyTorch requires the features to have similar dimensions, so we use unsqueeze(1) to add superficial 1 dimension to the tensor at the index 1 dimension.
squeeze
The values remain the same, but now we’ll be able to concatenate them to the end of our feature matrix X
Join the feature cross vector onto the end of the input X
Now we’ve concatenated the product of the first and second columns of X onto the end of our X feature matrix. It has a new size of 1000 rows by 11 columns. The new 11th column is the product of the first two columns.
We’ll need to extend the neural network to take 11 features instead of 10. Let’s see how this affects training.
# Define the modelmodel = torch.nn.Linear(11, 1)dataset = TensorDataset(x_feature_cross, y)
# Define the data loaderloader = DataLoader(train_dataset, batch_size=500, shuffle=True)
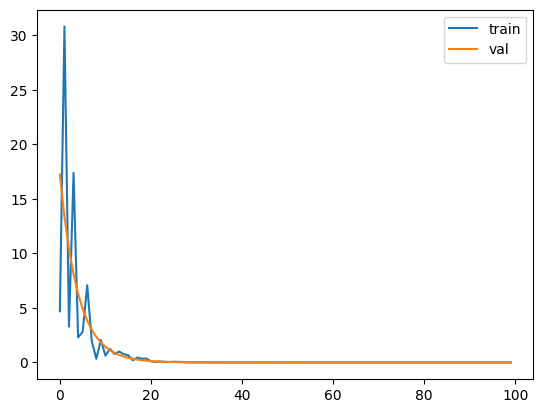
train(100, loader, model, val_x, val_y)
2.518, 1.761
The model converges towards a stable value, but it takes a long time and never reaches zero. This can be explained by the model not describing the mapping function perfectly - it is almost but not quite describing the equation
\(y=2X_0X_1 + 2X_0 -3X_1 - 3\)
Since we increased the number of layers in the model, interpreting what is going on by looking at the parameters has gone from being trivial to being very difficult. We are looking for coefficients which represent a straight multiplication of \(2 * X_0\), \(-3 * X_1\) and some way of representing \(2*X_0*X_1\)
Perhaps we can work out the correct set of parameters for the model just by thinking about it…
The first node of the first layer needs to carry through the exact values of \(X_0\) and \(X_1\) so they can be used later.
We also need these \(X_0\) and \(X_1\) features to be multiplied by the weights 2 and -3 for the linear part of the problem.
We’d need an overall bias of -3, which is added to the output layer of the model.
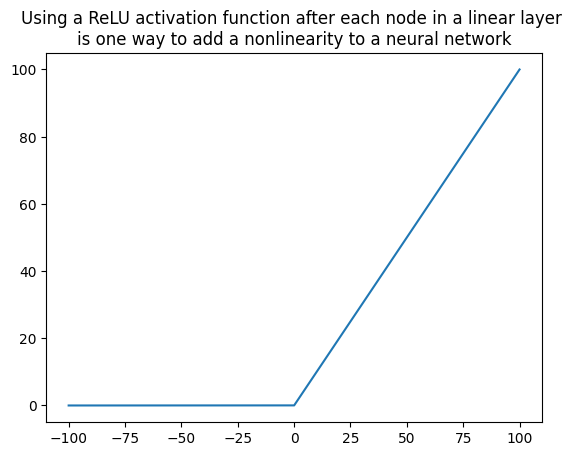
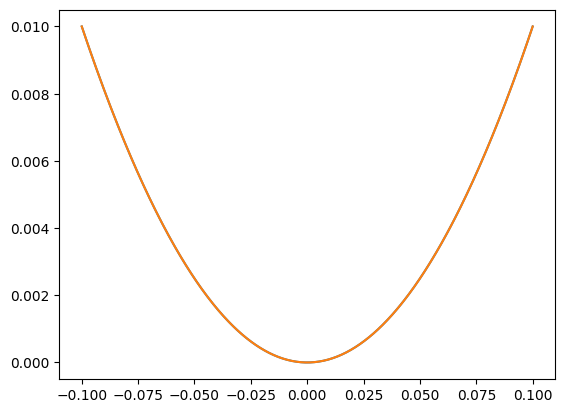
Finally need a point in the model where \(X_0\) and \(X_1\) are multiplied together. This never happens - unless we have a quadratic activation function. We’re providing nonlinearities using ReLUs (rectified linear units). A ReLU is like two linear functions (y=x and y=0) joined at a discontinuity at x=0.
k = torch.linspace(-100, 100, 20000)relu = torch.relu(k)plt.plot(k, relu)plt.title('Using a ReLU activation function after each node in a linear layer \nis one way to add a nonlinearity to a neural network')plt.show()
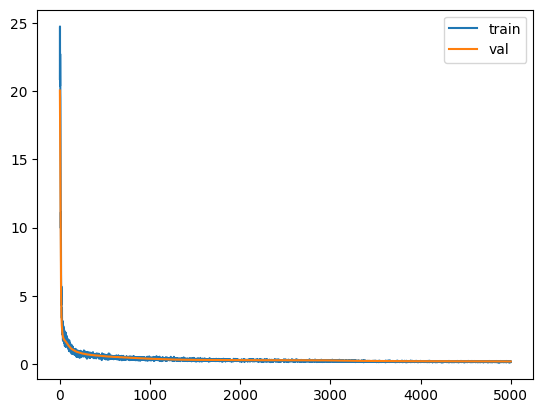
train(5000, loader, model, val_x, val_y)
0.172, 0.177
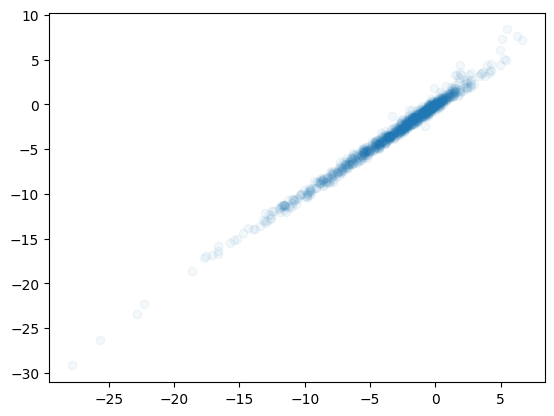
This model is trained pretty well. Let’s make a plot of y vs model(x) and see what shape we get.
plt.scatter(model(X).detach().numpy(), y, alpha=0.05)
<matplotlib.collections.PathCollection at 0x1378a83a0>
There are outliers visible. After training for 5000 epochs, the model has found a way of approximating our nonlinear function using a combination of coefficients and nonlinear activation functions. It isn’t perfect though - since functions which build the model are all linear additions and multiplications by ReLU.
Simplify the model to represent \(y=x^2\)
Having our nonlinearity in the form \(X_0X_1\) makes the problem space 3 dimensional, which is harder to plot. If we consider the case for \(y=x^2\) we’ll be able to see the model’s approximation more clearly.
<matplotlib.collections.PathCollection at 0x297771ab0>
I haven’t been able to get the model to train sufficiently for this problem. Here’s another blog post showing that it is possible, and that the resulting model doesn’t have any smooth segments on its curve:
Linear relationship between input features can be found efficiently by linear neural networks, even if there are multiple overlapping linear features.
Higher order functions of the form \(y=x^2\) and up, or crosses between input features of the form \(X_0X_1\) can only be approximated by neural networks - the nonlinearities are made by adding together a bunch of transformed nonlinear functions. In the case of ReLU, this means that the mapping will be made up of straight line segments.
Feature crosses can be used to provide a nonlinear mapping using a linear model.